import requests import random import easyocr from lxml import etree
# 请求头 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.63 Safari/537.36 Edg/93.0.961.47' }
# 接受课表页面数据进行解析 defparsing(text): html = etree.HTML(text) # print(text) for i in html.xpath('//*[@class="datalist"]/tr'): for j in i.xpath('./td/text()'): print(j)
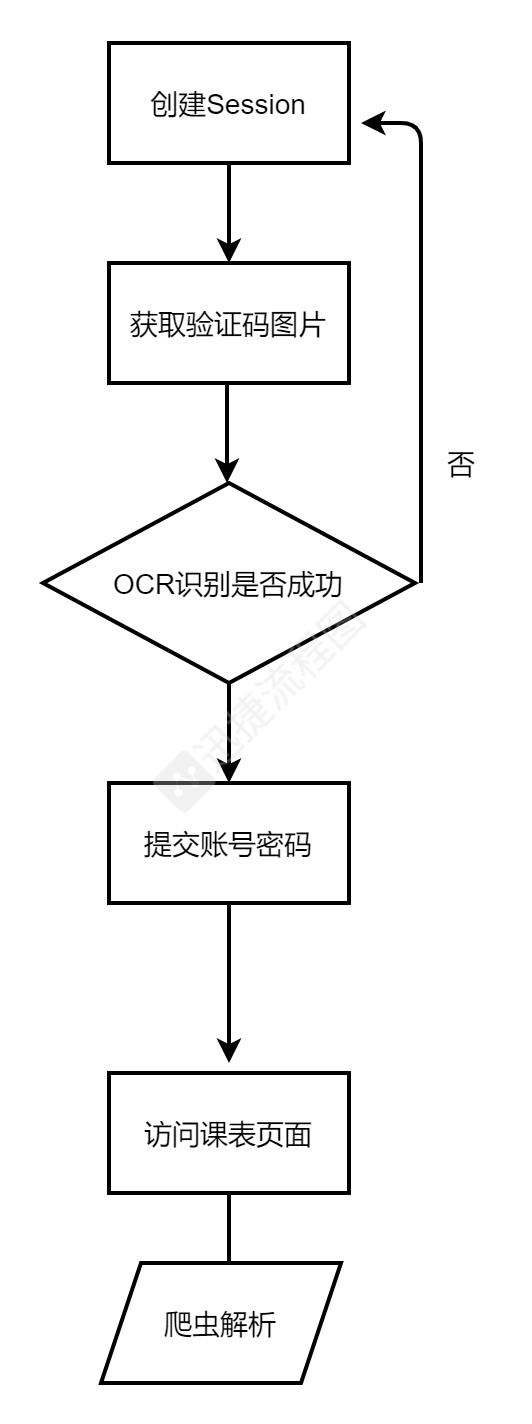
if __name__ == '__main__': table = '' whileTrue: # 创建一个会话 s = requests.Session() # 会话请求一张验证码 image = s.get(f'http://jw.glutnn.cn/academic/getCaptcha.do?{random.random()}', headers=headers) # 保存验证码到本地 withopen('getCaptcha.png', 'wb') as f: f.write(image.content) # 使用OCR识别验证码 reader = easyocr.Reader(['ch_sim', 'en']) result = reader.readtext('getCaptcha.png') # 接受验证码变量 captcha = '' # 读取验证码 for i in result: word = i[1] captcha = word # 登录时需要提交的数据,为账号密码,以及动态地填充验证码 data = { 'j_username': '**********', 'j_password': '**********', 'j_captcha': f'{captcha}' } # 在获取验证码后的会话进行验证OCR的结果 login = s.post(f'http://jw.glutnn.cn/academic/checkCaptcha.do?captchaCode={captcha}', headers=headers) if login.text == 'false': # 结果为假不进行操作 pass else: # 验证通过时执行登录操作 loging = s.post('http://jw.glutnn.cn/academic/j_acegi_security_check', data=data) # 进入个人课表页面,没访问这个页面无法进入本周课表页面 cu = s.get(f'http://jw.glutnn.cn/academic/student/currcourse/currcourse.jsdo?randomString=202109171926436Qv6aK&groupId=&moduleId=2000', headers=headers) # 访问本周课表页面 kb = s.get('http://jw.glutnn.cn/academic/manager/coursearrange/studentWeeklyTimetable.do?yearid=41&termid=3',headers=headers,data=data) parsing(kb.text) break